[ZK Lab] #1: Concept - Data Centric AI
in Study Blog on Zoran Kostic Lab
Data Centric AI
Definition
Data-centric AI is the discipline of systematically engineering the data used to build an AI system.
Data-centric AI Resource Hub
A place to share cutting edge techniques and best practices for using data centric AI methods to build successful machine learning systems.
Topics
Labeling and Crowdsourcing

- Suggestions:
- Label many of the examples yourself before designing the task.
- Pay and treat your workers fairly.
- Always start with small pilots.
- Always assume that the annotators are trying hard to build a model of your intentions: when something goes wrong, your reaction should be “what did I do wrong in communicating my intent?”, not “why weren’t they paying attention?”
- Train with feedback.
- It can often make sense to hire fewer people, more full time.
Data Augmentation
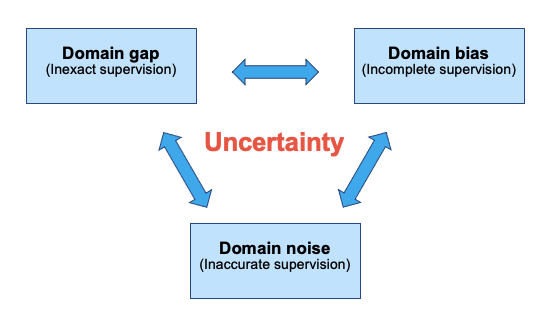
- Data limitations:
- Domain gaps: The data you train your model with is quite different from the data you have to predict on in the real world.
- Data bias: When the data you collect has imbalances due to societal bias, how can you design methods that can overcome them?
- Data noise: Noise can come from a variety of sources, including where labels are ambiguous, cluttered, or otherwise corrupted.
- Definition of Data Augmentation:
- Self-Supervision: When you have limited labeled data, you can try combining it with unlabeled data.
- rotation
- cropping
- Synthetic Data: While synthetic data is still in its infancy, there has been ongoing advances in generative models and it will become hugely important in the future for testing systems such as autonomous driving or robot learning.
- Self-Supervision: When you have limited labeled data, you can try combining it with unlabeled data.
- Data-centric principles in data augmentation:
- Core: the balance of positive and negative examples.
- Also: combine self-supervision with weak supervision.
Data in Deployment
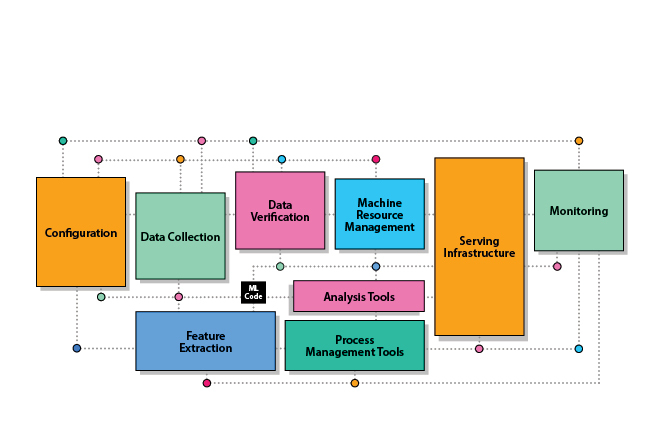
- Technical debt in machine learning:
- The concept of technical debt originally comes from the world of software engineering, where it has often been found that pushing to develop software very quickly can create long term maintenance costs that must be paid back later, and that if left unaddressed can compound over time.
- ML code – the bit that we tend to think of as the cool part – is actually a small component of the overall system.
- In a lot of settings it is not actually statistically useful to get more data.
- Three places to start:
- Audit and monitor data quality.
- Create data sheets for data sets.
- Create and apply stress tests using data.
